| 日志异常检测初步实践与探索 | 您所在的位置:网站首页 › drain sewer区别 › 日志异常检测初步实践与探索 |
日志异常检测初步实践与探索
|
1 背景 日志的主要目的是记录系统(包括服务和业务等)状态和重要的事件帮助定位系统的问题。日志对于理解系统状态和定位性能问题至关重要。因此,日志是在线监控和异常检测的一个重要信息源。在很多业务和服务的故障自愈过程中,日志异常检测与根因分析是必不可少的一环。但是之前我们通常都使用人工的方式来定位问题,主要包括人工检测与分析和人工学习错误日志提取正则表达式来进行故障定位这两种方式。 由于学习错误日志来提取正则表达式需要SRE同学对所负责的服务很了解而且对于每一种服务都需要人工学习它的日志,所以正则表达式在很多服务上还没用起来,我们主要还是人工去定位问题。长期受手动排查问题困扰的我们也在思考,有没有一些通用的自动的方式解放我们的双手和眼睛呢?在这样的背景下,我们对行业前沿的一些方法结合我们自己的运维经验开始了尝试和探索。 一开始,我们尝试了一些日志异常检测的主流深度学习算法比如DeepLog和LogAnomaly,它们的主要思想是异常时日志会和平时不同,可能是日志本身内容变化,也可能是日志顺序变化。 日志内容变化:异常时会出现平时不出现的日志模板(模板的概念,第二段会详细讲解)。 日志顺序变化:异常时日志中模板出现的顺序和正常时不同。 这种思想确实是很先进的,但是最后一公里的问题不好解决。具体来说,就是这些深度学习算法可以输出存在异常日志的一批日志序列,但是怎么从中提取真正的异常日志,进而提取具体的异常原因,又是一个难题。 使用这些深度学习算法进行日志异常检测的一个前提是提取日志模板。但是,提取日志模板就已经能够应对日志内容变化这种场景了:因为异常日志和正常日志通常不会在一个聚类,所以提取日志模板,对日志进行聚类就可以提取到异常日志(如果存在的话)。所以目前,我们选择日志聚类这种简单,便捷,相对通用的方法来做异常检测,先解决日志内容变化这种情况。
基于日志聚类进行完整的故障自愈流程如下图:
首先,报警触发故障自愈程序。当服务或者业务发生异常触发报警后,falcon的callback(回调)功能会把报警的服务,集群,报警项等相关信息一起发送给我们的故障自愈程序; 然后,收集待检测日志。故障自愈程序会根据具体的集群定位到集群配置来收集报警时一段时间的日志----待检测日志,并准备进行模板提取。这里提取日志模板就是对日志进行聚类。如果一批日志对应同一个日志模板,则认为它们属于同一个聚类;反之,是不同聚类; 接着,聚类待检测日志进行异常检测。假定我们收集到了尽可能多的正常日志,并提取了几乎所有正常日志模板,即有了几乎所有的正常日志聚类。对于新的待检测日志,如果属于正常日志聚类,则是正常日志;如果待检测日志里存在日志不属于任何一个已有的日志聚类,就会产生新的聚类,我们就认为这些日志大概率是异常日志。如果得到了异常日志,我们就能够相对容易地定位到异常原因,进而根据具体的异常原因,进行自动处理。处理完成后,报警得到恢复。 2 提取日志模板 1 日志模板的概念
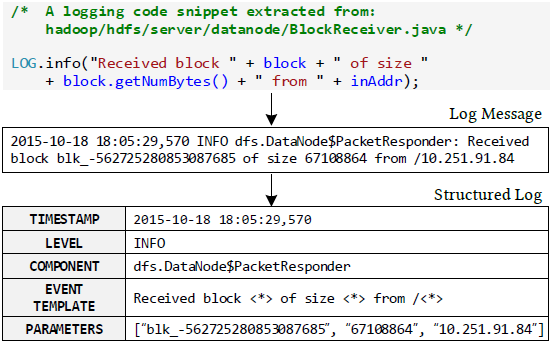
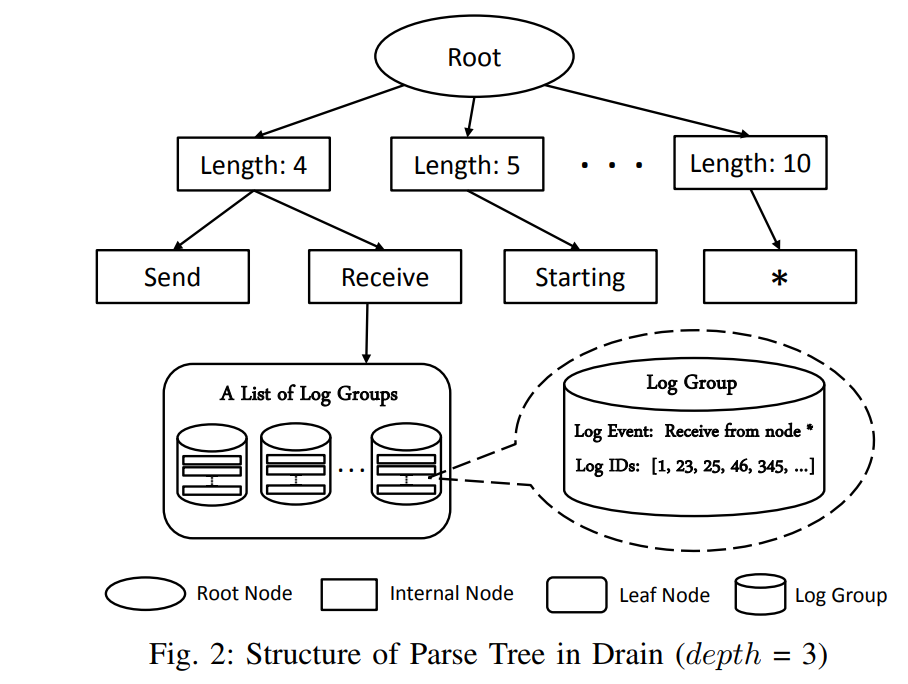
因为日志本身是无结构的文本,所以日志分析的第一步就是将日志转化成有结构的数据。每一个日志信息通过时间戳,日志级别和日志内容等记录一个具体的系统行为。将时间戳,日志级别等关键信息提取出来很容易,但是将真正的日志内容结构化就有一定的难度了。 通过对比上图第一部分,我们可以看到,日志内容是由不变的字符串和可变的值构成的。不变的部分就是我们要提取的日志模板,每一次系统执行这段代码时,这一部分都是一样的。可变的部分代表着动态的运行信息,可能会随着集群和机器这些不同而改变。日志数据结构化的目标就是把每一个日志信息转化成具体的模板和参数,就代表着每一个参数的位置,如上图第三部分EVENT TEMPLATE所示。 2 Drain 提取日志模板部分我们使用了目前性能比较好的Drain算法,一个在线的日志模板提取方法。Drain的核心思想是基于日志数据构建一个固定深度的解析树,这个树里蕴含了具体的模板提取规则。 输入一个新的日志,Drain会先对它进行预处理,主要是提取出时间戳,日志级别等信息。这一部分基于简单的正则表达式实现。预处理之后就可以建树了,下图就是一颗根据输入日志建的树。 根节点和内部节点编码了具体的搜索规则。解析树的每一条路径都以一个叶子节点结束,下图重点描绘了一个叶子节点。每一个叶子节点里存储了一堆的log group,每一个log group有两部分:log event和log ids。log event是一个日志模板。log ids记录了符合当前log event的日志id。新日志进来后,主要通过搜索最匹配的log event来提取日志模板,并更新树。详细过程就不再赘述,感兴趣的同学可以阅读Drain原论文。
3 Drain的改进 1)使Drain实现增量学习
因为对于同一种服务日志来说,日志越多,提取到的日志模板越准确,但是日志越多,提取时间也就越长。综合考虑,我们必须能让Drain记住之前从日志中学习到的规律。 具体来说,每次重新提取模板时,要接着建树,而不是从头建树。模板中蕴含了我们从日志中提取到的规律,所以我们把Drain算法基于每一种服务日志提取的模板都保存起来,下一次再需要提取这种服务日志模板时,直接根据已有模板重建树就可以实现不重新训练但是依旧能够利用之前的服务日志中的信息。 因为日志模板数目是常数量级,所以基于模版重建树的使用几乎可以忽略不计。Drain的新版本Drain3版本直接把树保存起来,也可以不用重新训练。但是基于模板重建树,更加灵活。比如,有些模板提取错误,只需要修正这些模板,下次根据模板重建树时,树的结构也会更正。 2) 合并分错的模板
当参数在靠前的位置,并且参数中不包含数字时,就很容易出现下面这种情况:本应该是同一个模板,结果却分成了多个模板。我们结合Drain的特点,作了如下改进。在同一个长度划分的子树的所有叶子节点里,对于出现次数特别少的模板,如果存在模板的相似度大于设定的阈值,则按照更新parse树中的步骤合并更新这些模板。
3 日志异常检测 1 提取正常日志模板 首先要收集大量的正常日志,我们收集了大量非报警期间的日志作为正常日志。基于Drain算法,使用正常日志来建树,在建树的过程中就提取了正常的日志模板。如果服务的代码会定期更新的话,每次更新后,还需要再收集正常日志,继续提取模板。为了提高效率,我们把每种服务基于Drain提取的日志模板分别保存了起来。对于具体的服务,再次训练时只需要基于保存的日志模板重建树,就能接着训练。既能利用之前的信息又不用从头开始建树,大大节省了时间。
2 提取待检测日志模板 首先收集待检测日志,默认收集报警后一分钟的日志。同样可以基于当前服务已保存的日志模板,来接着建树,对待检测日志提取日志模板。
3 异常检测
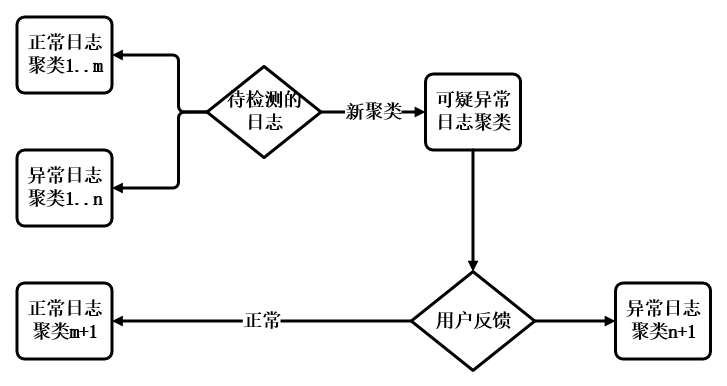
在没有标记的情况下,我们先粗略地认为非报警期间的日志就是正常日志。使用日志聚类算法,基于正常日志形成若干聚类。对于报警后新产生的一批日志,如果都能够聚类到已有的正常日志聚类里,那它们自然都是正常日志;如果有新日志聚类到了已有的异常日志聚类,则是异常日志。如果有日志形成了新的聚类,我们就认为新聚类的日志是可疑的异常日志,推送给相关SRE同学。如果SRE反馈,这些日志依然是正常日志,那么就会标记成一个新的正常日志聚类;反之,就是一个新的异常日志聚类,如果SRE能够顺手标记一下属于哪种异常,后续我们就可以直接推送具体的异常原因给SRE同学,进而可以根据具体的异常原因,进行相关处理,加快问题解决的速度,提高运维效率。 4 根因分析 由于缺乏报警与故障原因的相关性数据,我们这里处理得比较简单,主要考虑机器问题。我们认为异常日志里出现次数最多的机器就是最可疑的机器,这一部分可以根据实际情况提取具体的故障信息。 5 算法效果
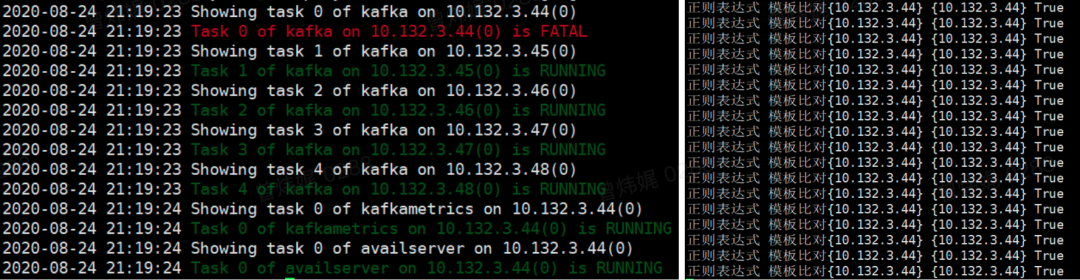
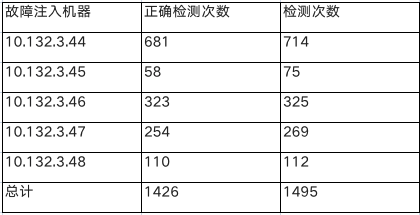
我们在kafka一个有五台机器的测试集群上,轮流对每台机器做故障注入,一共试验了 1495 次,准确率是 95.38%。上面左图是一台机器被故障注入时集群的状态,右图是当前故障注入机器对应的ip A和我们异常检测算法检测到的机器ip B的记录日志。 具体的实验数据如下表所示,第一列是故障注入机器ip A;第二列是算法检测到的机器ip B与ip A相等的次数,即正确检测次数;第三列是当前机器被故障注入后触发报警进而触发故障自愈程序进行检测的次数。通过多次故障注入,总的正确检测次数除以总检测次数就是我们算法的准确率。
以上是我们在kafka上的试验效果,具体服务上的效果可能波动比较大,主要受日志数据质量的影响。一般来说,日志数据越规范,效果会越好。 6 适用服务 我们的日志异常检测方法适用的服务理论上只需要满足两个条件:异常时会出现新的日志模板;异常日志里有引起异常的原因。简单来说,正则表达式适用的服务,我们的方法都适用,但是不需要人工去收集异常日志,然后写正则表达式。像hdfs/hbase/yarn/zk这种开源的、日志比较规范的服务,可以多加尝试。我们建议平时总是能从日志定位到问题的服务,可以优先尝试此方法。 7 优势 在适用的场景下:比人工检测快;比正则表达式通用;准确率高。 8 规划和愿景 由于定位问题通常需要结合日志和监控(KPI),所以我们也探索了一些KPI异常检测算法,并做了一些尝试。目前来看,效果还可以,不过还需要继续优化,寻找更多的应用场景。接下来,我们会结合具体的用户需求,继续探索异常检测与根因分析前沿算法,最终希望80%重复出现的问题能够自动定位到原因。 参考资料: 1)Drain: An Online Log Parsing Approach with Fixed Depth Tree https://github.com/logpai/logparser/tree/master/logparser/Drain 2)DeepLog: Anomaly Detection and Diagnosis from System Logs through Deep Learning 3)LogAnomaly: Unsupervised Detection of Sequential and Quantitative Anomalies in Unstructured Logs
|






【本文地址】